

Imaginez que vous disposiez d’un grand tableau de données : en ligne, des individus (ou des observations), en colonne, des variables qui les caractérisent. Le tableau est grand, il comporte de nombreuses lignes. Il pourrait aussi comporter de nombreuses colonnes, mais ce n’est pas notre problème dans un premier temps. Et vous n’avez aucune connaissance a priori sur la structuration des observations.
Des groupes de points
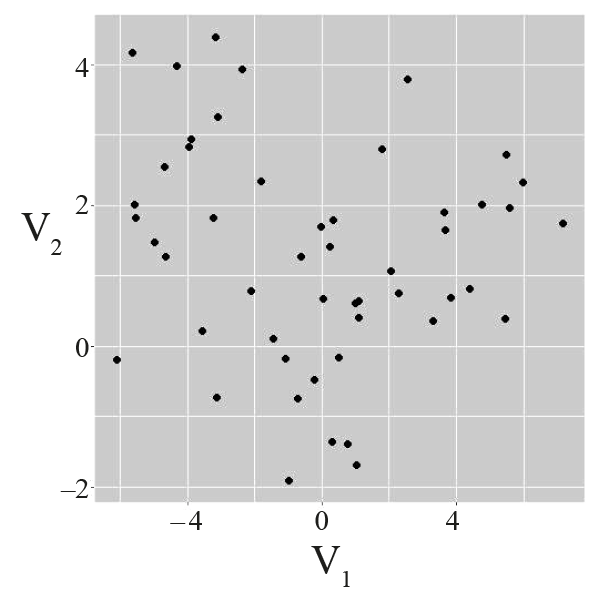
À l’extrême, et parce que c’est plus facile à visualiser, considérons qu’il ne comporte que deux colonnes, qu’elles concernent deux variables quantitatives (qui se mesurent), appelées V1 et V2. Une observation représente donc un point dans ℝ2. Afin de bien appréhender ces données, il est possible de résumer chacune des variables (moyenne, écart-type) et de les représenter sur une figure, V1 sur l’axe des abscisses et V2 sur celui des ordonnées.
Une information très intéressante se dégage de l’exemple du haut ‒ on y voit trois groupes très distincts ‒, tandis que dans celui du bas, tout semble ne former qu’un seul amas. L’exemple du milieu est intermédiaire : on pourrait définir trois groupes, mais les frontières ne sont pas claires.
.png)

Un ordinateur pourrait-il automatiquement ... Lire la suite